Eureka服务发现问题的另一种解决方式
21 May 2017服务发现为什么不用zookeeper?
类似的问题网络上已经有很多资料,这里就不在详细解释。只谈以下几点: zookeeper本质上是一个CP系统,在多节点的情况下Leader选举比较耗时,并且会放大network partition 的问题。一旦分区出现时,在某个partition中 quorum 的数量不能满足多数派协议先决条件时,zookeeper client 会与server失联。但也并不是没有解决办法,可以尝试在客户端做cache来做些弥补。总而言之一句话:zookeeper本质上为了解决分布式系统中为了某个值达成一致而设计,在这种前提下一致性是首要的需求。而对于服务发现跟服务注册来说,保证最大的可用性是第一位的。严格的来说在一个CP系统上来构建一个AP系统并不是最好的解决办法。
Eureka High Level Architecture
Erueka是基于REST的服务发现注册组件。轻量,方便与应用整合是其最大的特点。在实际的运行环境中Eureka跟Server Provider在同一个JVM进程内。在Eureka中主要包括以下几类角色:
- Eureka Server :真正提供发现服务的实体,对外暴露REST接口,提供服务注册,发现,续约,服务下线,剔除无效节点等服务。
- Service Provider :服务提供者,可以是任何微服务的业务提供方。
- Service Consumer :从Eureka获取服务注册的地址列表。
在Eureka中有些概念比较容易混淆:在Eureka中是不区分服务的Client跟Server的,他们都是Eureka Client ,有些应用可以将自己注册在Eureka中,但并不对外提供服务,因为只是想用调用其他服务端。所以在Eureka中Instance是指能够被其他“Client”发现的服务提供方,一个应用程序既可以是Eureka Client(发现其他服务) 又可以是Eureka Instance(提供业务服务给其他客户端).
可见在微服务的环境中,服务提供方与服务使用方必须是从耦合的,服务的消费一方甚至不用感知这些服务的真是地址,所有的服务变更,fail over,load balance 都是由类似 Eureka的中间层来做的。下面是Eureka的高层架构图。
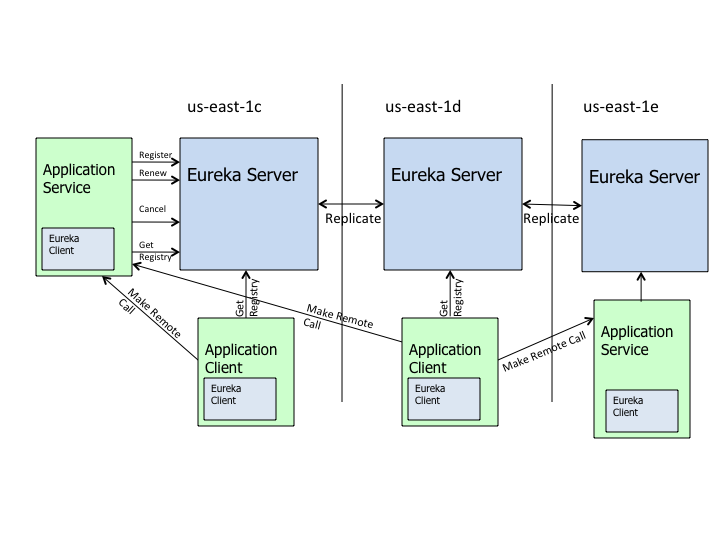
Eureka的server之间角色是对等的。并不是遵循典型的master-slave架构,一个Eureka Server在Eureka被称作PeerEurekaNode,Eureka的Cluster是由一个个PeerEurekaNode所构成。那么问题来了?在这种对称架构中所有的节点都能够对外提供同样的服务,因此各个节点看到的系统状态要尽量的保持一致,这也是分布式系统设计的挑战一直——如何在大规模集群中做好协调和同步?
Eureka 点对点通讯及Fail Over
对于上文提到的问题,通常的做法是提供一个类似“集群管理服务”来解决此问题,有一个共享的持久化存储来保存状态信息(在本文中主要是服务提供者的状态变更信息),然后Eureka Node的各个节点可以lazy式(只在需要的时候)的查询这些状态信息,然而高性能系统的一个普遍的设计原则是:要尽可能的避免在关键路径上的RPC(这里面的RPC是泛指的)尤其是在要求吞吐跟性能的场景下,这些远程访问的成本通常被服务提供者的负载所影响(当然还有处理网络连接的成本)。在这个问题上Eureka采取的策略是——可用性第一,状态并未持久化,允许客户端看到不同的数据视图,进一步解释就是,看到过期的数据总比没有任何数据都好。这也是Eureka作为服务发现有别于zookeeper的一个地方。
Eureka在peer to peer communication 模式下是 ** 如何处理network partition ** 问题的呢?当Eureka Server上线的时候,会尝试从他的临近节点的服务注册表中获取信息,如果这个环节出错,则Eureka Server会放弃当前的server从其他的剩余节点中查询一段时间内有哪些服务可用(5分钟之前有哪些服务可用)。正常情况下Eureka server 之间会通过心跳来保活(与zookeeper中的临时节点类似),如果检测到心跳失败,Eureka Server 会进入到一种自我保护状态,在这种状态下新服务可以继续注册,但是“过时”的服务将被保留下来,在网络恢复后,节点之间通过信息交换来纠正这些不一致。 这实际上也是一种类似客户端cache的方案,具体服务的死活是由真正的服务消费者来判断的。
总结:对于Eureka来说,可用性第一,任何时候都不会反回给客户端空的服务列表,状态信息在内存中保存,是一个嵌套的Map结构。在网络出问题的时候尽可能的对失败保持弹性,允许客户端看到不一致的数据视图。