Druid架构分析(一)
10 Dec 2016Druid是啥?跟阿里的那个Druid一毛钱关系都没有。Druid是个实时OLAP分析引擎。针对时序数据处理优化。这是InfoQ的介绍文章Durid InfoQ
1.关于时间序列数据
为什么要有时序数据库?time series database这是关于时序数据库在维基百科上面的定义。我试着从数据使用的角度朴素的分析一下。如果暂且把非时序数据称为归档数据或交易数据的话,这一类数据通常是人为产生,或者由机器低频度产生。时序数据与之相反,典型的是传感器产生的大量数据:比如智能电表,手机传感器,机器Log等。所以从数据规模上来说,时序数据大很多,在使用方式上看两类数据也有本质的区别。
读取,时序数据以时间为第一查询维度,数据使用方式以多维度聚合为主,没有点查询(比如按照主键查询某一条记录)。通常来说返回结果需按照时间排序。理论上一个合格的时序数据库,按某一时间范围检索数据的性能,仅与该时段的数据大小有关,与总数据大小关系不大。
写入,时序数据的写入通常是多个数据源持续实时写入。多个数据源(比如智能电表)时间并未校对,所以写入的数据很有可能是乱序或者基本有序。
修改或者删除,时序数据的不可变特定没有数据修改的需求,也不涉及单条记录的删除,有超期淘汰的功能。
对于时序数据的存储,RDBMS就显得力不从心。在RDBMS中,B+-Tree及其衍生树是用的比较多的索引数据结构。树节点只存放Key,数据在叶子节点,这样会使树节点的度比较大,所以树的高度比较低。方便查找。当数据大量膨胀叶子节点就会分裂——破坏数据在磁盘上的连续性,在做范围查找的时候会产生大量的随机IO。关系数据库解决这类问题通常的做法是:写入降速——DB之前有MQ中间件,存储时候降维度——并不存储原始数据,预先聚合。 其他方案:
1.1 时序数据库要解决的问题
对于一个分布式的存储系统,有几个问题是绕不开的。
- 数据如何存储,如何分布——引擎,分片和路由
- 数据一致性,完整性——副本的策略,一致性协议如何选择
- 高性能,必须高可用,必须可恢复。
对于时序数据存储还必须解决时序数据顺序的问题,及如何避免数据热点。
Druid主要组件及其功能
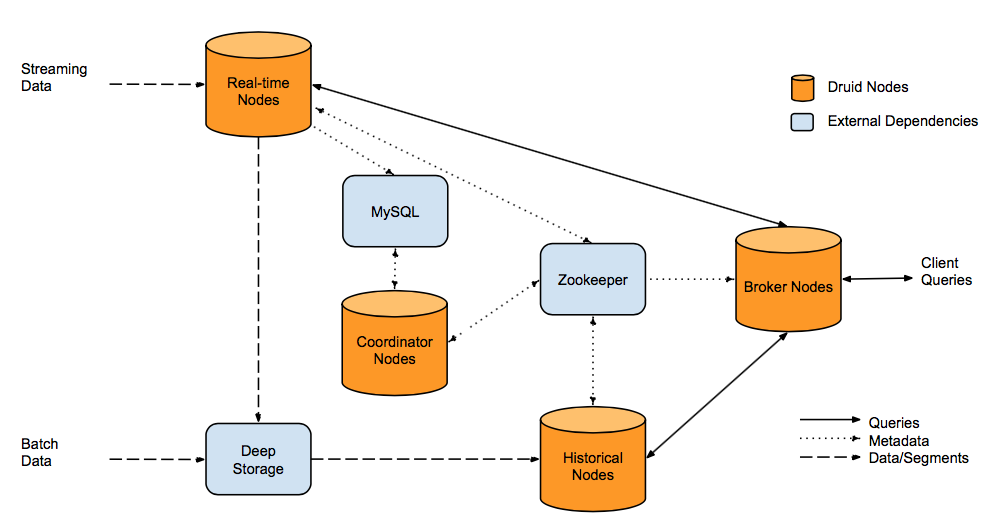
其中黄色节点是Druid本身的组件,其余的是外部依赖,各节点的主要功能:
- Real-time Nodes,负责实时数据的写入,生成Segment文件。
- Historical Nodes,加载已经生成的Segment文件,主要提供查询功能
- Coordinator Nodes,负责Historical Nodes的运行时负载,数据生命周期的管理。
- Broker Node,对外提供查询服务,负责汇总Real-time 与 Historical的数据给客户端。
- MySQL,用于存储元数据。
- DeepStorage,通常为HDFS等分布式文件系统,永久存储Segment。
在接下来的几篇文章里,会用简单的语言来描述一下Druid各个组件的功能及其的核心关注点。